In thinking about the problem of metadata, I was reminded of an old discussion -- addressed already in Protocol but worth repeating -- easily summed up by the expression "metadata = data."
What I mean by this formulation is that no media-infrastructural mechanism exists to distinguish between data and metadata. First and foremost, one can't distinguish them formally: there's no information type α called "data" separate from another type β called "metadata" through which one might distinguish the one from the other.
Computer Scientists are, in this sense, monists. They never invented two categories of things, only the one category (the bit) which has to do double duty as everything under the sun. Such is the great strength of digital computation -- as Alan Turing said, the universal machine can do the work of any other machine -- but it's also the great limitation of digitality. How does a machine know if anything is different from anything else, if it only has one thing?
The answer is: artifice. Scientists superimpose an artificial *structure* to data; structure means that one "kind" of data remains separate from another "kind" of data. Yet while structure and form are necessary conditions of digitality, they are not rigorous mathematical instruments, and thus can't be deployed as a categorically different type.
So "metadata = data" is true formally. It's also true practically: every bit of data may have some adjacent bit of "metadata"; yet in most cases that meta bit is simply the kernel of a larger data glob, which itself will likely have its own metadata. The nested structure of network packets are a good example: the "metadata" of ASCII text are HTML tags; but an HTML page itself is assigned new "metadata" in the form of an HTTP header; then that entire thing (ASCII-HTML-HTTP data all wrapped up) gets a TCP/IP header as metadata, which gets a frame header based on the physical network medium.
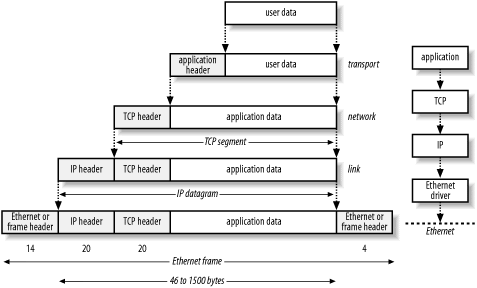
So, in a sense it's metadata all the way down, or, if you prefer, all the way up as well. Or not "all the way" since things peter out at the level of electrons (down there) and semiotic signs (up here). But, regardless, the designation "metadata" is a relative designation rather than an absolute one -- a little like the drawing of a rabbit, which, if you see it differently, might also be a duck. Anything called "metadata" will most certainly be mere "data" if you move your perspective a little bit. And likewise anything called "data" will most certainly do double duty as some kind of "meta" wrapper for something else further down the chain.
What does this mean for states and companies? Clearly claims like "we don't listen to the calls we only look at the metadata" ring hollow. (First, we already know it's a false claim; they listen to the calls as well. Not to mention that there is a tremendous amount of information embedded within so-called metadata, so much, in many cases, that the data "contents" can be interpolated to a high degree of probabilistic certainty.) The question is how and why this claim rings hollow. The answer is that, following the nesting architecture above, it's always ambiguous where the data stops and the metadata begins. Likewise we know that any kind of "data" can simply be spun as "metadata" if you move your frame a little bit. The data-metadata distinction quickly becomes ideologically vague, and therefore a strategic vulnerability that may be exploited by state and commercial actors.
But these are all implementation problems best left to the engineers... In a future post I'll try to move on to other problems, problems having to do with the question of framing, the so-called critical stance, and the question of meaning. Is metadata a problem for thinking?